

W Apache Spark mamy 3 podstawowe struktury: Dataset, Dataframe, RDD. To na nich operujemy, jeśli chcemy przetwarzać dane i to właśnie w nie „wciskamy” nasze dane. Dzisiaj wyjaśnię krótko, na czym one polegają i jakie są między nimi różnice.
Co istotne – nie będę się zagłębiał w każdą ze struktur z osobna. Temu posłużą osobne materiały! Tutaj chcę, żebyśmy zdobyli ogólny ogląd i umieli odróżnić je od siebie.
Struktury Sparkowe #
Sens struktur Sparkowych #
Podstawowa idea jest taka, że Spark wykonuje za nas całą robotę rozproszoną. My mamy jedynie pomyśleć nad tym jak to logicznie ugryźć, natomiast architektonicznie praca z wieloma maszynami jest zrobiona „w pakiecie” z samego faktu, że korzystamy ze Sparka.
Ale aby tak się stało, musimy korzystać z jego struktur. To funkcje, które są tam przygotowane, choć wyglądają często podobnie do funkcji scalowych, w rzeczywistości zawierają logikę pracy w trybie rozproszonym. Tak więc funkcja „map()” nie będzie tą samą „map()” co wywołana na liście scalowej – mimo, że efekt będzie identyczny, to cała implementacja została przez twórców sparka zrobiona od nowa.
Warto to mieć na uwadze, bowiem czasami kusi, aby przestać używać struktur sparkowych i zamienić je na scalowe/pythonowe. W rzeczywistości prowadzi to do tego, że przestajemy korzystać z trybu rozproszonego, a cały kod odbywa się na driverze.
RDD #
Pierwsza, najbardziej podstawowa, to Resilient Distributed Datasets, w skrócie RDD. Pisząc „najbardziej podstawowa” mam na myśli dwie rzeczy:
- Chronologicznie pierwsza – kiedyś korzystano jedynie z RDD. Z czasem doszły pozostałe.
- Na RDD opierają się obie pozostałe struktury. Czyli jeśli dokopiemy się odpowiednio daleko w kodzie, prędzej czy później dojdziemy właście do RDD. Co nie oznacza, że możemy odpuścić tamte!
Swoją budową, przypominają odrobinę taką rozproszoną „listę”. To znaczy nadajemy im typ, a następnie pracujemy z konkretnym elementem – np. we wspomnianej wyżej funkcji map().
Zróbmy bardzo prostą operację przy użyciu RDD:
val namesList: Seq[String] = Seq("marek", "kasia", "ignas", "jozio", "roza", "zygmunt", "arek", "julia")
val namesRDD: RDD[String] = spark.sparkContext.parallelize(namesList)
val namesBig: RDD[String] = namesRDD.map(n=> n.toUpperCase) // map - transformacja
namesBig.take(5) // take - akcja
.foreach(println)Dodajmy, że „spark” jest instancją SparkSession.
W ten sposób najpierw stworzyliśmy sztuczne RDD z SEQ. Następnie wywołaliśmy funkcję map() która zamienia każdy element (który jest napisame – String) na taki sam, ale pisany wielkimi literami.
W świecie rzeczywistym, zamiast 8 imion, moglibysmy mieć nawet 80 miliardów imion – po 10 propozycji na każdego człowieka na świecie. Takie RDD mogłoby nam się nie zmieścić na laptopie – ale na rozproszonym klastrze już bez problemu. Co fajne, wtedy ten kod wyglądałby dokładnie tak samo!
RDD pokazuje nam tutaj swoje podstawowe oblicze – możemy nadać typ taki, jaki chcemy. I traktujemy każdy element „osobno”. Jest to bardzo wygodne, ponieważ jesteśmy przyzwyczajeni do tego typu manipulacji ze scali, javy czy pythona. Szczególnie, jeśli jesteśmy zaznajomieni z programowaniem funkcyjnym.
Warto jednak podkreślić, że RDD są najmniej wydajną strukturą sparkową! Przejdźmy zatem do czegoś mniej zasobożernego.
Dataset #
Przejdźmy do zupełnie innej struktury. Datasety mają postać tabularyczną. Są po prostu klasycznymi tabelkami, gdzie są kolumny. Kolumna ma z kolei swoją nazwę, typ i nullable (czy może zawierać NULL czy nie). Warto przypomnieć, że Datasety „pod spodem” mają działające RDD.
W związku z formą struktury, funkcje których możemy użyć, są zupełnie inne. Nie skupiamy się już na działaniu na pojedynczym elemencie, ale na „ugryzieniu” całej tabeli. Przykładowo, mamy tu do czynienia z dobrze znanymi z SQLa agregacjami – np. „groupBy(„name”).count()” sprawia, że dostaniemy podliczenie ile jakich imiona mamy w tabeli.
Dataset – co bardzo ważne – także może mieć swój typ. Może być to bardzo przydatne, gdy chcemy pracować w projekcie ze z góry zdefiniowanymi modelami. W przypadku scali możemy zrobić case class, jak poniżej:
case class Car(brand: String, year: Int, model: String, price: Int)Następnie, gdy stworzymy Dataset[Car], będzie on zawierał kolumny brand, year, model, price. I każda z nich będzie miała typ taki, jak przeznaczyliśmy w modelu.
Dataset posiada 2 funkcje, które pozwolają nam „podejrzeć” jak on wygląda.
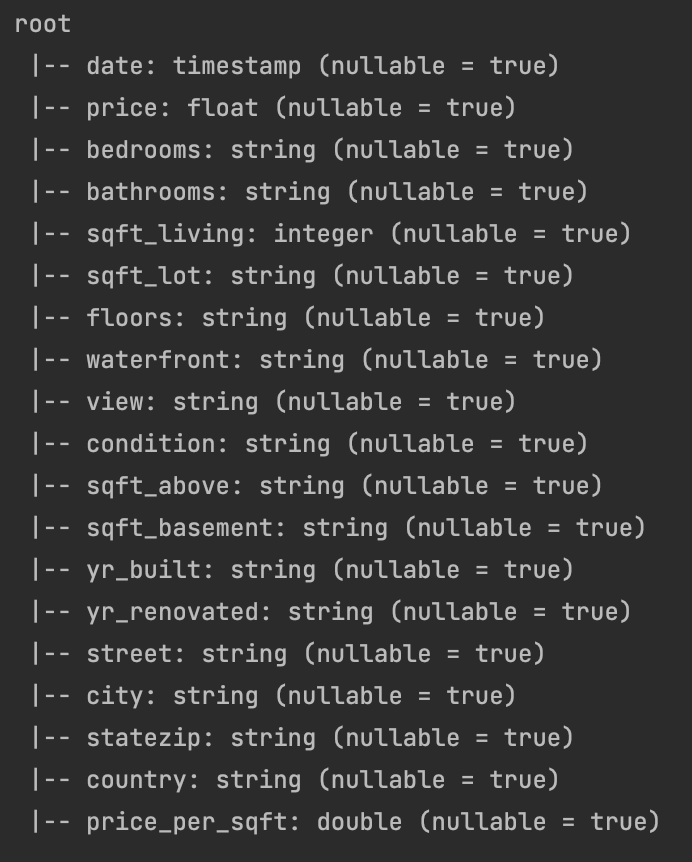
- printSchema – drukuje na ekranie schemat datasetu
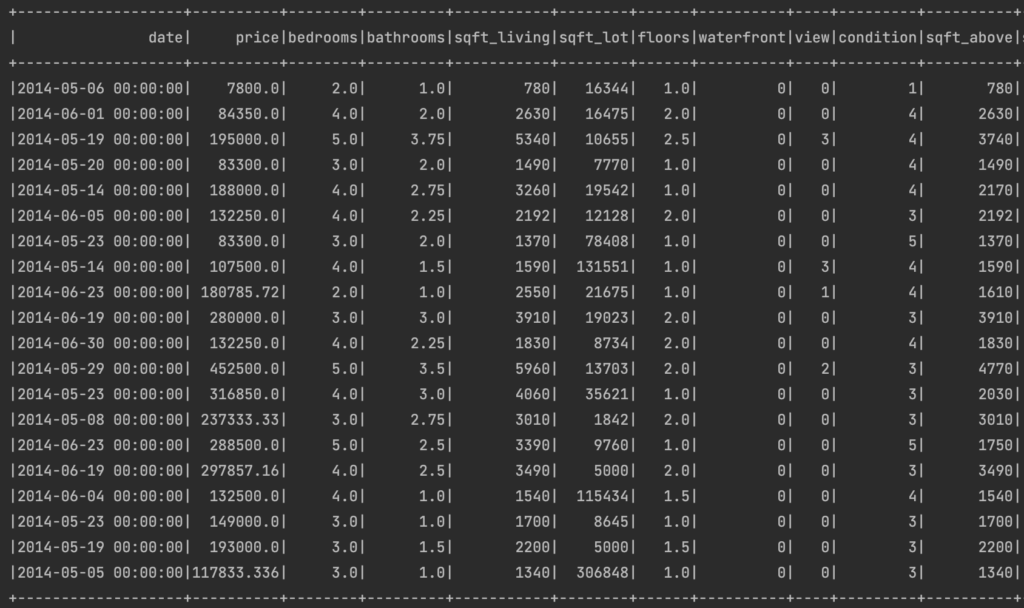
- show() – pokazuje 20 pierwszych wierszy datasetu. UWAGA! Show() jest akcją!
Przykład działania show():
Przykład działania printSchema():
Warto wspomnieć, że niestety akurat datasetów nie spotkamy w pySparku.
Datasety są już bardziej wydajnym tworem niż RDD. To jednak nie jest jeszcze „gwiazda sparka”!
Dataframe #
Ostatnia struktura, obecnie najczęściej wykorzystywana w Sparku, to Dataframe’y. Jest to także struktura tabelaryczna, podobnie jak Datasety. Tyle tylko, że w tym przypadku nie możemy określić typu. Nie wchodzi więc w grę tworzenie osobnych klas-modeli.
Wychodzi więc, że dataframe to taki dataset, tylko gorszy, prawda? Na szczęście nie. Dataframe’y są najlepiej zoptymalizowanymi strukturami w Sparku!
Tak naprawdę, wybór między Dataset a Dataframe jest niezbyt dobrze opisany. A to dlatego, że Dataframe to… specyficzna postać Datasetu! Konkretnie, twórcy sparka stworzyli osobny typ – Row – a następnie zrobili Dataset[Row], dla którego aliasem jest Dataframe.
Dzięki temu, że zastosowany jest ten konkretny typ, inżynierowie sparka mieli możliwość żeby popracować nad nim i – dzięki zastosowaniu specjalnego silnika (Catalyst) – Dataframe’y działają najlepiej. Wszystko to kosztem czytelności (brak jasno wymuszonych kolumn), ale i tak sprawdzają się dobrze w większości projektów.
Z okazji tego, że Dataframe jest szczególnym przypadkiem Datasetu, wynika jeszcze jedna rzecz: mają wspólne api. Tak więc, wszystkie funkcje które możemy zastosować na Dataset, możemy także na Dataframe i odwrotnie. Zresztą konwersja jednej struktury w drugą jest bardzo prosta (i nienajlepiej zrobiona domyślnie, ale to temat na inny materiał;-)).
A jak stworzyć swój, przykładowy dataframe w scali? Poniżej cały kod:
val spark: SparkSession = SparkSession.builder()
.appName("iqvia-spark")
.master("local")
.getOrCreate()
import spark.implicits._
val people: Seq[(Int, String, String, Int)] = Seq((1, "marek", "czuma", 30), (2, "andrzej", "czuma", 35), (3, "kasia", "nowak", 19), (4, "marek", "jarek", 30))
val peopleDF: Dataset[Row] = people.toDF("id", "firstName", "lastName", "age")
peopleDF.show()Pokazuję razem z inicjalizacją SparkSession z jednego powodu: bardzo ważna jest linijka import spark.implicits._
To dzięki niej zyskujemy funkcję „toDF()”, która pozwala zamienić SEQ na dataframe. Koniecznie należy to zrobić po inicjalizacji spark sesji.
Podsumowanie #
W Sparku mamy 3 różne struktury:
- RDD – przypominają nieco „listę”. Nadajemy im tym, przetwarzamy zbiór myśląc o każdym elemencie „z osobna”.
- Dataset – postać tabularyczna. Także możemy nadać typ. Bardziej wydajne niż RDD.
- Dataframe – szczególna postać Datasetów (Dataset[Row]). Także tabelka, ale nie wymusimy tam jasnej, z góry określonej struktury. Jest to najlepiej zoptymalizowana struktura w Sparku.
Pytania do aktywnej powtórki #
- Jakie struktury znajdziemy w Sparku? Scharakteryzuj każdą z nich.
- Która struktura jest najlepiej zoptymalizowana?
- Które struktury są tabularyczne, a które nie?
- Którym strukturom możemy narzucić typ?
Mam nadzieję, że materiał pomógł Ci zrozumieć tą tematykę!




Responses